
- Harsh Maur
- December 2, 2024
- 7 Mins read
- Scraping
Playwright DOM Selection: Best Practices
Want to make your Playwright scripts more reliable and easier to maintain? Start by mastering DOM selection. This guide explains how to choose the best locators, avoid common pitfalls, and improve your web scraping automation scripts.
Key Takeaways:
-
Use semantic locators like
getByRole()andgetByLabel()for stable and accessible element selection. - Avoid overly specific selectors (e.g., auto-generated IDs or complex CSS paths) to reduce maintenance headaches.
- Leverage locator chaining for precise targeting in complex DOM structures.
- Handle dynamic content and Shadow DOM with Playwright's built-in tools.
- Debug and refine your selectors using Playwright Inspector.
Quick Comparison of Locator Types:
| Locator Type | Pros | Cons |
|---|---|---|
| Semantic Locators | Stable, readable, accessible | Limited to supported attributes |
| CSS Selectors | Fast, flexible | Brittle with DOM changes |
| XPath | Powerful, supports backward traversal | Slower, harder to maintain |
Pro Tip: Always prioritize semantic locators for better script stability and readability. Dive into the article to learn detailed strategies and advanced techniques for DOM selection.
Playwright selectors in-depth for beginners (with best practices and examples)
Understanding Locators in Playwright
Locators are a key part of Playwright’s DOM selection process, allowing you to interact with web elements stably and efficiently. They form the backbone of reliable web automation and testing.
Types of Locators
Playwright offers two main approaches for selecting elements: user-facing attributes (like getByRole, getByLabel, getByText) for semantic and accessible selection, and traditional methods like CSS selectors and XPath for detailed control. Here’s an example:
await page.getByRole('button', { name: 'Submit' });
await page.getByLabel('Username');
Comparing CSS Selectors and XPath
| Feature | CSS Selectors | XPath |
|---|---|---|
| Performance | Faster execution | Generally slower |
| Flexibility | Limited to forward traversal | Supports both forward and backward traversal |
| Maintainability | More resistant to changes | Can easily break with DOM updates |
While CSS selectors and XPath have their use cases, user-facing attributes provide a more modern and resilient way to interact with elements.
Using User-Facing Attributes
User-facing attributes improve stability, readability, and accessibility. These selectors are designed to reflect how users naturally interact with a page, making them an excellent choice for automation tasks.
"Prioritize user-facing attributes like
getByRoleandgetByLabelfor better maintainability and reliability." - Playwright Best Practices, Bondar Academy
For dynamic content, you can combine these attributes with locator chaining for more precise targeting:
await page.locator('div.parent >> css=span.child');
Mastering these locator strategies is essential for building reliable and maintainable test scripts. Next, we’ll dive deeper into best practices for DOM selection.
Best Practices for Selecting DOM Elements
After discussing locator types earlier, let's dive into some practical tips for creating selectors that are reliable, easy to manage, and efficient.
Use Semantic Locators
Semantic locators focus on elements' roles and labels, making them more stable and easier to maintain than IDs or class names. They also align with accessibility standards, which is a win for both usability and compliance.
// A reliable semantic locator
await page.getByRole('button', { name: 'Post comment', exact: true });
// A less reliable, implementation-specific locator
await page.locator('#submit-btn-47892');
Why choose semantic locators?
- Easier to maintain: They’re less likely to break with HTML updates.
- Accessibility-friendly: They support ARIA standards.
- Clearer code: The intent is obvious, making it easier for teams to collaborate.
Avoid Overly Specific Selectors
Selectors that are too specific can lead to brittle scripts that break with minor changes. Here’s a quick look at some risky selector types:
| Selector Type | Example | Risk Level |
|---|---|---|
| Auto-generated IDs | #ember-123-4567 |
High - Changes often |
| Complex CSS paths | .header div:nth-child(3) > span |
High - Breaks with layout tweaks |
| Multiple class combos | .btn.primary.large.special |
Medium - Affected by styling updates |
Use Locator Chaining
Locator chaining helps you zero in on elements within complex DOM structures by combining broader and more specific locators.
// Example of chaining locators
const commentSection = page.getByRole('region', { name: 'Comments' });
const replyButton = commentSection.getByRole('button', { name: 'Reply' });
Tips for effective chaining:
- Start with broad containers (like regions) and narrow down with specific attributes.
- Keep chains short to maintain readability.
- Use descriptive variable names that reflect the element’s purpose.
sbb-itb-65bdb53
Advanced Techniques for DOM Selection
Once you've mastered the basics, it's time to tackle the challenges of dynamic and complex web applications. These advanced techniques will help you navigate intricate DOM structures with ease.
Working with Dynamic Content
Dynamic content often involves frequent updates or asynchronous loading, which can complicate element selection. Playwright offers powerful tools like waiting mechanisms and flexible selectors to make this easier.
// Wait until dynamic content becomes visible
await page.waitForSelector('[data-testid="dynamic-content"]', { state: 'visible' });
// Use contains() for flexible text matching
const dynamicElement = page.getByRole('article')
.filter({ hasText: 'Updated content' });
Accessing Shadow DOM
Interacting with Shadow DOM elements can be tricky, but Playwright simplifies this process. Locator chaining allows you to target elements inside web components accurately.
// Select an element inside Shadow DOM
const shadowElement = await page.getByText('Details');
// Chain selectors through Shadow DOM
const nestedElement = await page.locator('custom-component')
.getByRole('button', { name: 'Submit' });
Creating Custom Selector Engines
For enterprise applications with unique frameworks or non-standard attributes, custom selector engines are a game changer. They streamline complex selection scenarios, making your tests cleaner and easier to maintain.
// Register and use a custom selector
await page.addInitScript(() => {
window.registerSelector('data-custom', {
query(root, selector) {
return root.querySelector(`[data-custom="${selector}"]`);
}
});
});
const element = await page.locator('data-custom=unique-id');
When building custom selectors, focus on:
- Speed: Ensure they perform efficiently.
- Reliability: They should work consistently across different scenarios.
- Maintainability: Keep the logic simple to reduce future headaches.
For debugging custom selectors, Playwright Inspector (npx playwright test --ui) provides real-time feedback, making it easier to refine your approach.
Tools and Resources for DOM Selection
Getting the hang of DOM selection in Playwright becomes much simpler when you have the right tools. Here's a breakdown of some key resources that can make selecting elements easier and more efficient.
Playwright Inspector
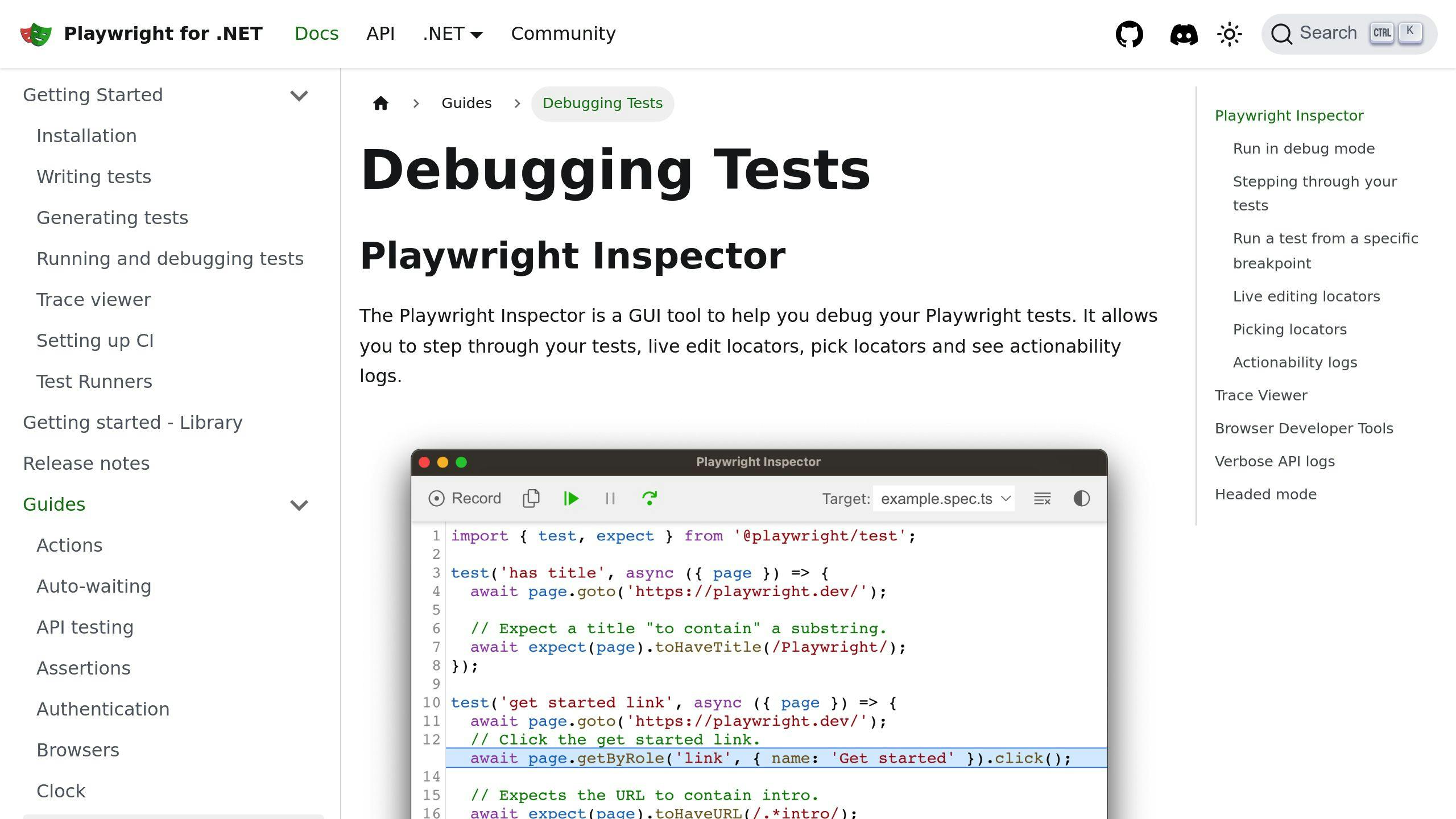
Playwright Inspector lets you test locators in real time, inspect element properties, and debug selectors interactively. It's a great way to fine-tune your scripts as you write them. To launch it, use:
npx playwright test --ui
Locator Picker Tool
The Locator Picker Tool, available through the Playwright VS Code extension and UI mode, helps you generate accurate locators automatically. It focuses on creating role-based selectors, user-facing attributes, and semantic locators to keep your scripts stable and easy to maintain.
const button = page.getByRole('button', { name: 'Submit' });
External Tools for Advanced Needs
If your project requires large-scale data extraction or features beyond Playwright's built-in tools, consider external platforms like Webscraping HQ. These tools can complement your workflow and handle more complex requirements. When choosing one, look at:
- API compatibility with your project
- Quality of available documentation
- Support for the websites you're targeting
- How well it scales for larger tasks
With these tools and resources, you can handle DOM selection more effectively, setting a strong foundation for advanced automation tasks.
Summary and Next Steps
Now that we’ve covered the essentials, let’s go over the main principles of DOM selection in Playwright and see how you can keep improving your scripts.
Key Points Recap
To make your Playwright scripts more reliable, focus on semantic locators like getByRole(), getByLabel(), and getByText(). These locators target elements based on their purpose rather than their position in the DOM, making them less likely to break when the structure changes.
Improving Scripts Over Time
Keeping your scripts in good shape requires regular checks and updates. Focus on these areas:
// Example of efficient locator chaining
const submitButton = page.getByRole('region', { name: 'Comments' })
.getByRole('button', { name: 'Post comment' });
Best practices to follow:
- Track test stability and make adjustments as needed.
- Use precise locator chaining to improve accuracy.
- Debug tricky selectors with Playwright Inspector.
- Update selectors when site structures change.
Additional Resources
For larger projects or more complex workflows, you might need tools beyond Playwright. Platforms like Webscraping HQ can handle advanced automation and large-scale data extraction tasks, complementing Playwright’s features.
FAQs
What is the XPath attribute in Playwright?
XPath in Playwright allows you to select elements based on specific structured conditions. While it offers flexibility, it tends to be harder to maintain compared to semantic locators.
# Selecting elements with a specific class using XPath
element = page.locator('//div[@class="myClass"]')
How do you select elements by CSS class in Playwright?
You can select elements by CSS class in Playwright using the locator() method:
# Examples of CSS class selection
element = page.locator('.myClass') # Single class
element = page.locator('.primary-button.active') # Multiple combined classes
Here are some tips for creating effective CSS selectors:
- Use semantic locators whenever possible.
-
Combine CSS selectors
getByRole()for more reliable results. - Keep your selectors simple and easy to maintain.
"Playwright can automatically detect that a CSS selector is being passed in as an argument. Alternatively, you can prepend your CSS selector with css= to make sure Playwright doesn't make a wrong guess."
Whether you're using XPath or CSS selectors, always aim for stability and ease of maintenance by integrating Playwright's semantic locators into your approach.